機械学習の分類手法の一つ、サポートベクターマシンとは何か?

サポートベクターマシンの前に最大マージン分類器について
サポートベクターマシンを説明する前に最大マージン分類器から話を始めねばならない。
最大マージン分類器、サポートベクター分類器、サポートベクターマシンの順番に説明していかないとサポートベクターマシンのよさが伝わらない。
最大マージン分類器とは、マージンを最大化する分類器のこと。
では、マージンとは何か?
マージンとは、データを分類する境界線からデータまでの距離のこと。
データを区切る境界線はいくつか引くことができるが、データからの距離が最大化するように規定された境界線が、最大マージン分類器と呼ばれる。
参考ウェブサイト
データを二分して区切る線形の分類器は、二次元なら直線、三次元なら平面、四次元以上は超平面になる。

出典:https://onlinecourses.science.psu.edu/stat857/node/240
この画像の黒線が最大マージン分類器。
赤の点と青の点からもっとも離れている。
赤い線も緑の線もちょっとずれると赤の点や青の点に触れてしまう。
誤分類が起こりやすい。
誤分類が起こりにくそうなのは黒線。
分類器として優れていそうな黒線が、最大マージン分類器になる。
サポートベクターマシンの前にサポートベクター分類器について
最大マージン分類器は、上図のようにきちんと二分割できないと使えない。
きれいに二分割できるデータばかりではないので、現実問題として使いにくい。
サポートベクター分類器は、その点、きちんと二分割できなくてもOKで、誤分類を認めることにした線形の分類器。
最大マージン分類器より応用範囲が広がった。
誤分類をどのくらい認めるかで、分類器の予測性能も決まってくる。
誤分類をなるべく認めないかなりきわどい線にすると、学習データではあてはまりがよくても、テストデータであてはまらないという過学習が起きてしまう。
テストデータの当てはまりが、予測性能。
機械学習の目的は、予測性能の高い分類器を作成することなので、テストデータの当てはまりは重要。
誤分類をある程度認め、新たなデータにも当てはまる、分類器を作ることを目指している。

サポートベクターマシンとは?サポートベクター分類器との違いは?
サポートベクターマシンは、サポートベクター分類器と同じ、誤分類はある程度認めたうえで、さらに、境界が非線形。
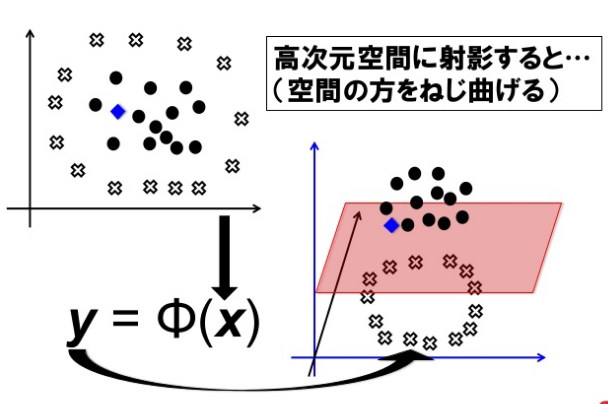
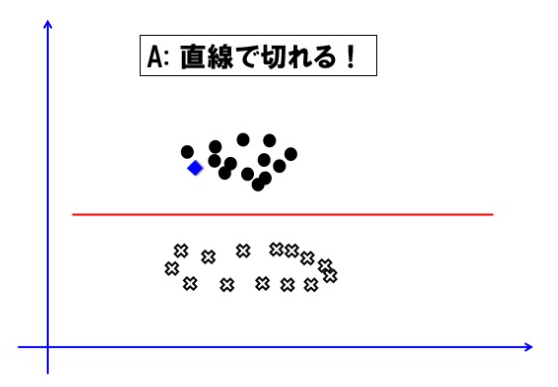
出典:https://www.slideshare.net/tojimat/tokyor-41
上記の図は、非線形の関数を使って分類するイメージ図。
サポートベクターマシンは、線形の関数では決して分類できない状況でも分類する方法を考えてくれる方法。
サポートベクターマシンも複雑性を増しすぎると過学習してしまうため、分類精度を保持しつつ、予測精度も確保するために、クロスバリデーションが必要になる。
まとめ
機械学習のための分類器の一つに、サポートベクターマシンがある。
サポートベクターマシンの大元は、最大マージン分類器。
最大マージン分類器の弱点は、二分割完全にできないと使えない点。
二分割できない場合に誤分類を認めたのがサポートベクター分類器。
線形分類器のサポートベクター分類器を、非線形分類器に拡張したのがサポートベクターマシン。